create table SELECT <逗号分隔的列名列表> FROM <表名> ORDER BY <列名> [ASC | DESC] 默认是升序排序的。
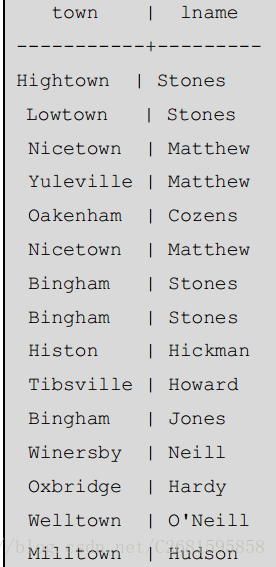
原始数据如下表,后续讲解,都使用该数据。
尝试给输出的列重新命名:
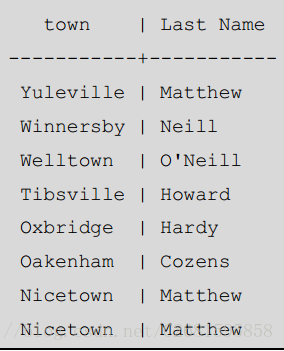
SELECT town, lname AS "Last Name" FROM customer ORDER BY town; 重命名效果:
同时按照不同的列和不同的方式排序排序
语法:
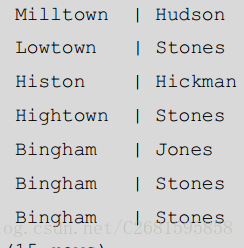
SELECT town, lname AS 'Last Name' FROM customer ORDER BY town DESC, lname ASC; 效果:
实现原理:
就像你看到的, PostgreSQL 先将数据按 town 的降序排列,因为它是 ORDER BY 从句后面的第一个列。然后它将相
同 town 里头有多条记录的数据按升序排列。这时候,虽然 Bingham 是在检索到的数据的末尾,但其中的客户的姓仍然是
按升序排列的。
通常,你可以用来排序的列被强制限制于你选择用于输出的列(看上去不无道理)。但至少到当前版本的 PostgreSQL
未知,不强制执行这一标准限制,它可以接受用于 ORDER BY 后面的列不在你选择的列的列表里头的情况。但是,这是
非标准 SQL,所以我们建议你避免使用这个功能。
###使用任何聚集函数 SELECT 语句都可以包含两个可选的从句: GROUP BY 和 HAVING。语法如下(在这里使用了count(*)函数):
SELECT count(*), 列名列表 FROM 表名 WHERE 条件 [GROPY BY 列名 [HAVING 聚集条件]] ##count使用
###count(*)
SELECT count(*) FROM customer WHERE town = 'Bingham'; ##尝试使用group by
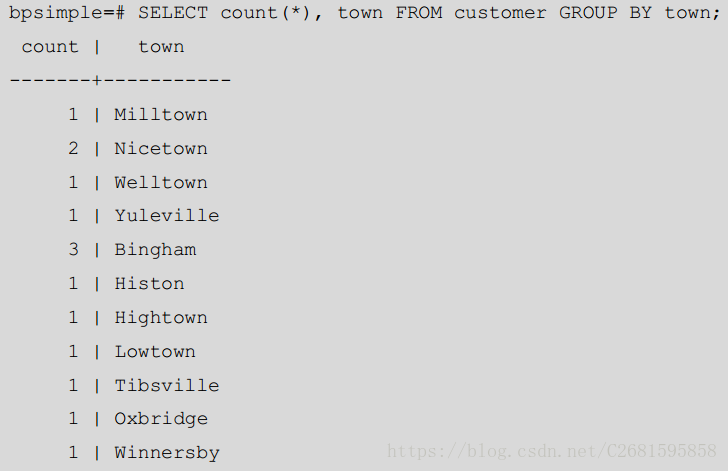
让我们尝试回答“每个城镇有多少客户?”这个问题
SELECT count(*), town FROM customer GROUP BY town; 结果:
他是怎么实现的:
PostgreSQL 按照 GROUP BY 从句里的列将结果排序。它然后保存一个行数的计数器,每次城镇名字改变,它就写
出结果集并且重置计数器为零。你会认同这比写代码循环查询每个城镇来统计结果更容易。
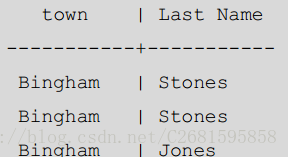
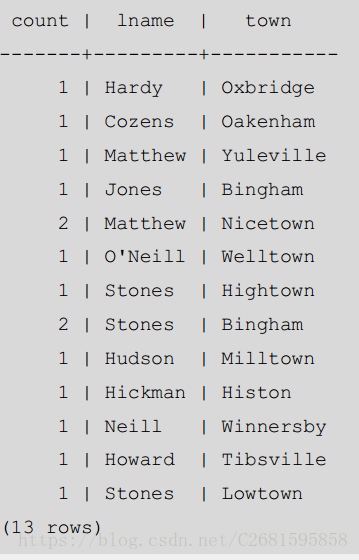
**如果我们需要,我们可以扩展这个想法到超过一个列,将我们所有选择的列都列在 GROUP BY 从句中。假设我们想知道两块信息:每个城镇有多少姓相同的客户。我们可以简单的在语句中的 SELECT 和 GROUP BY 部分添加 lname **
SELECT count(*), lname, town FROM customer GROUP BY town, lname; 效果展示:
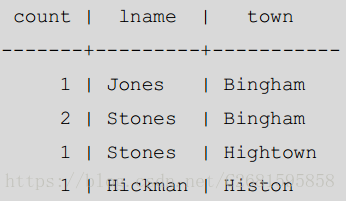
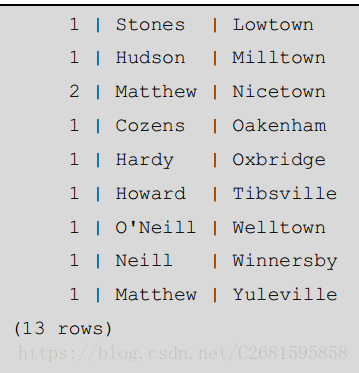
注意 Bingham 列出了两次,因为在 Bingham 住有两个客户有不同的姓,分别是 Jones 和 Stones。还要注意输出是不排序的。在 8.0 版本之前的 PostgreSQL 会按 town 排序,然后是 lname,因为这是他们在 GROUP BY 从句中的顺序。PostgreSQL 8.0 以及以后的版本,我们需要更明确地通过 ORDER BY 从句指定排序顺序。我们可以通过这样获取排序的输出:
SELECT count(*), lname, town FROM customer GROUP BY town, lname ORDER BY town, lname; 结果展示:
##having从句和count(*)
聚集无法使用在 WHERE 从句中。他们只能用在 HAVING 从句中。
假设我们想知道有超过一个客户的城镇。我们可以使用 count(*),然后直接查看相关的城镇。但是,在有成千上万的城镇的情况下,这不是一个合理的方案。作为替代,我们使用一个 HAVING 从句来约束结果为 count(*)大于一的行,就像这样:
SELECT count(*), town FROM customer GROUP BY town HAVING count(*) > 1; 效果展示:
##尝试使用having